OpenResty 高性能的原因
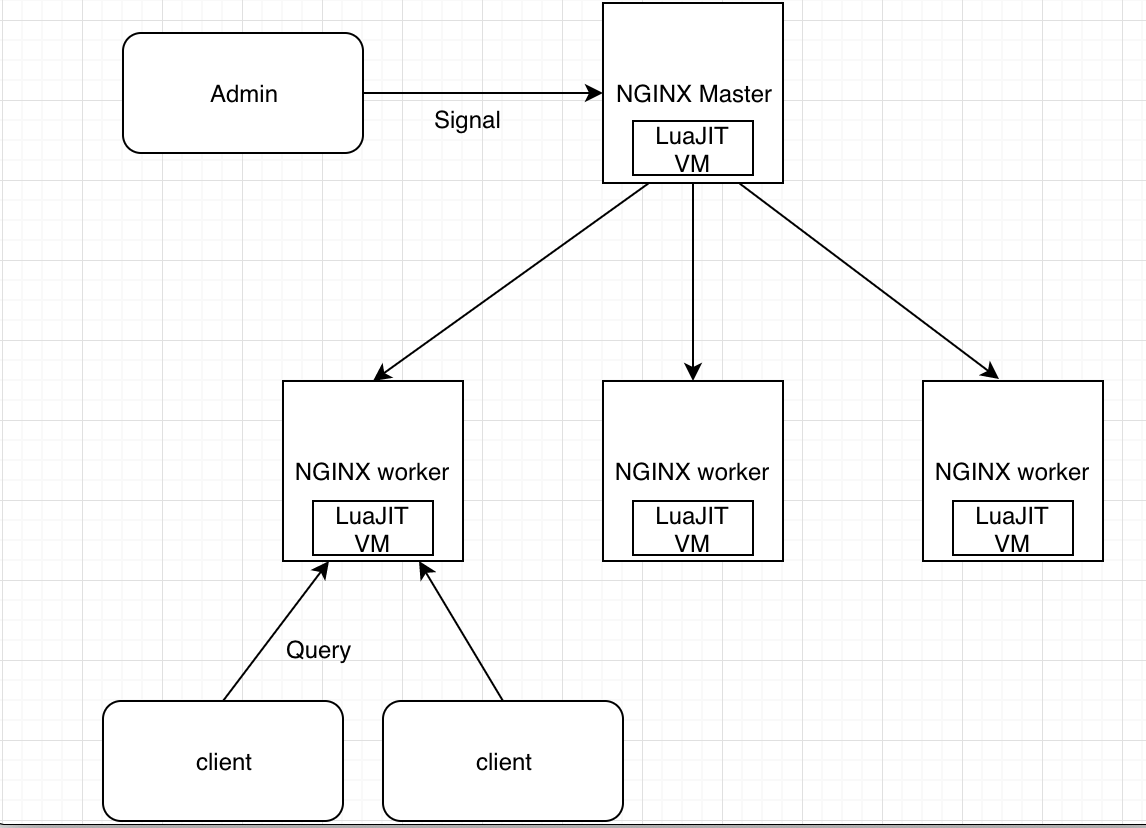
运行在 Nginx 整体架构之上
OpenResty 的 master 和 worker 进程中,都包含一个 LuaJIT VM。在同一个进程内的所有协程,都会共享这个 VM,并在这个 VM 中运行 Lua 代码。
而在同一个时间点上,每个 worker 进程只能处理一个用户的请求,也就是只有一个协程在运行。
NGINX 实际上是通过 epoll 的事件驱动,来减少等待和空转,才尽可能地让 CPU 资源都用于处理用户的请求。
毕竟,只有单个的请求被足够快地处理完,整体才能达到高性能的目的。
如果采用的是多线程模式,让一个请求对应一个线程,那么在 C10K 的情况下,资源很容易就会被耗尽的。
cosocket
是 OpenResty 的核心和精髓。
在早期的 OpenResty 版本中,如果想要去与 Redis、memcached 这些服务交互的话,需要使用 redis2-nginx-module、redis-nginx-module 和 memc-nginx-module这些 C 模块。
这些模块至今仍然在 OpenResty 的发行包中。不过,cosocket 功能加入以后,它们都已经被 lua-resty-redis 和 lua-resty-memcached 替代,基本上没人再去使用 C 模块连接外部服务了。
实际上,cosocket 是 OpenResty 中的专有名词,是把协程和网络套接字的英文拼在一起形成的,即 cosocket = coroutine + socket。
cosocket 是各种 lua-resty-* 非阻塞库的基础,没有 cosocket,开发者就无法用 Lua 来快速连接各种外部的网络服务。
cosocket 不仅需要 Lua 协程特性的支持,也需要 Nginx 中非常重要的事件机制的支持,这两者结合在一起,最终实现了非阻塞网络 I/O。
如果我们在 OpenResty 中调用一个 cosocket 相关函数,内部实现便是下面这张图的样子:
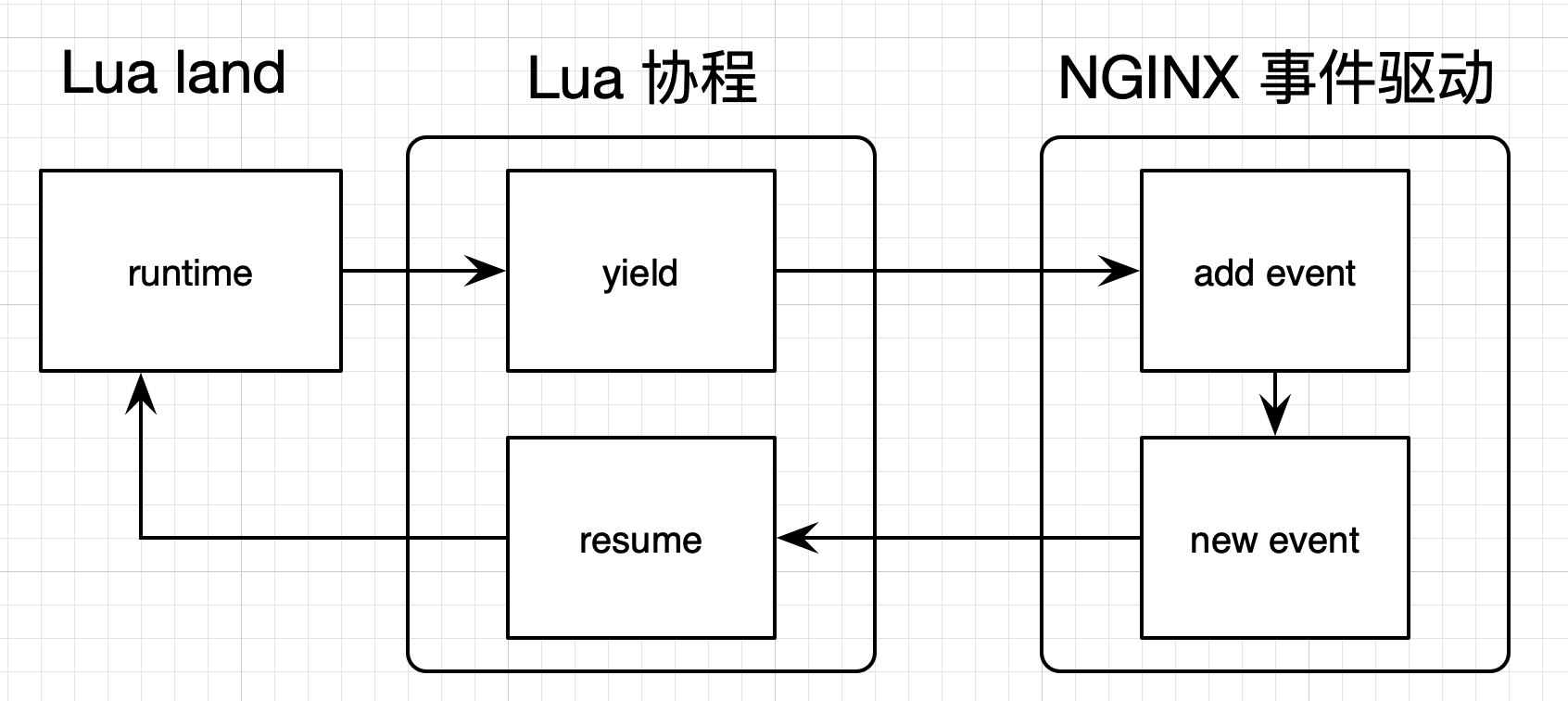
遇到网络 I/O 时,它会交出控制权(yield),把网络事件注册到 Nginx 监听列表中,并把权限交给 Nginx;当有 Nginx 事件达到触发条件时,便唤醒对应的协程继续处理(resume)。
cosocket API 和指令简介
- 创建对象:ngx.socket.tcp。
- 设置超时:tcpsock:settimeout 和 tcpsock:settimeouts。
- 建立连接:tcpsock:connect。
- 发送数据:tcpsock:send。
- 接受数据:tcpsock:receive、tcpsock:receiveany 和 tcpsock:receiveuntil。
- 连接池:tcpsock:setkeepalive。
- 关闭连接:tcpsock:close。
这些 API 可以使用的上下文:
rewrite_by_lua*, access_by_lua*, content_by_lua*, ngx.timer., ssl_certificate_by_lua, ssl_session_fetch_by_lua*_
在某些阶段是不能使用的,比如 init_by_lua,log_by_lua*,参考 Cosockets Not Available Everywhere
LuaJit
通过 tracing 对热代码进行编译。
LuaJIT 在 OpenResty 整体架构中的位置
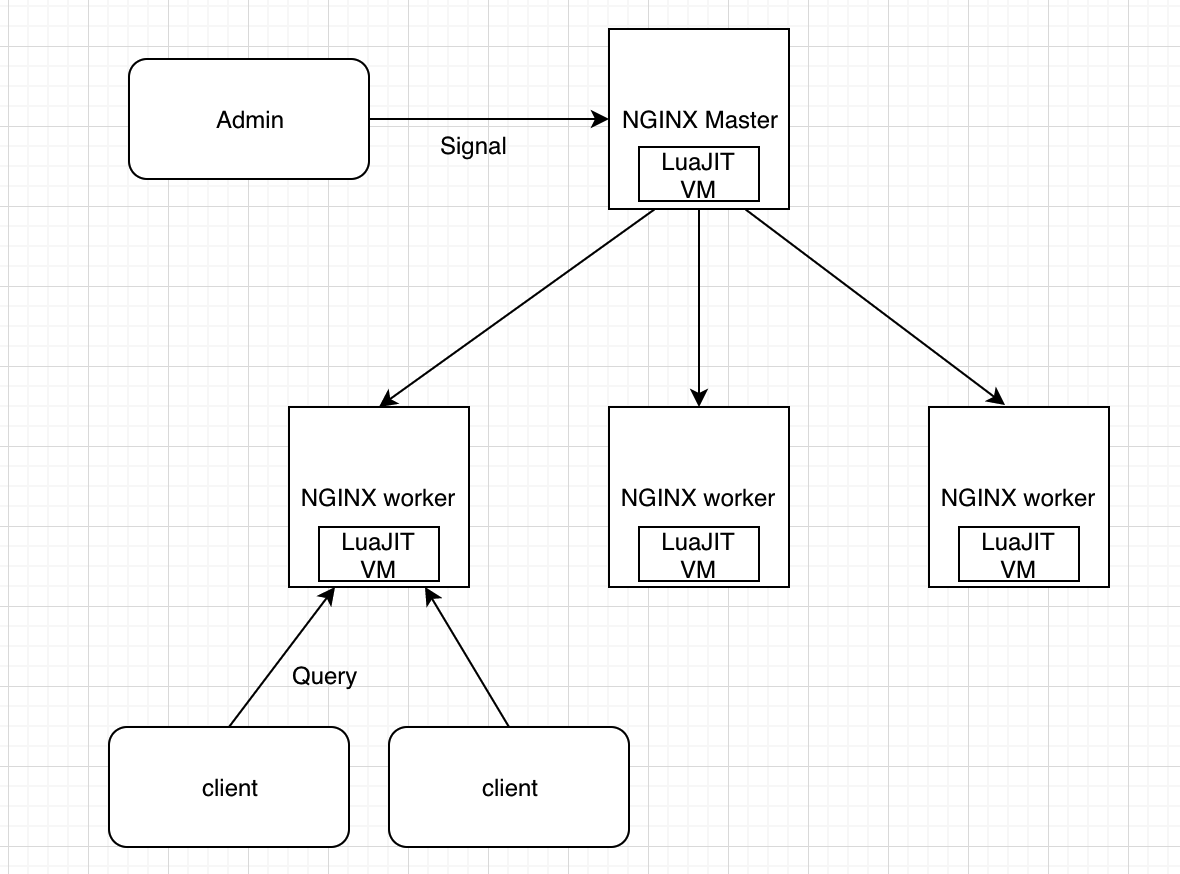
OpenResty 的 worker 进程都是 fork master 进程而得到的,master 进程中的 LuaJIT 虚拟机也会一起 fork 过来。
在同一个 worker 内的所有协程,都会共享这个 LuaJIT 虚拟机,Lua 代码的执行也是在这个虚拟机中完成的。
LuaJIT vs Lua
标准 Lua 和 LuaJIT 是两回事儿,LuaJIT 只是兼容了 Lua 5.1 的语法。
在 OpenResty 中,可以用 Lua C API 来调用 C 函数,还可以在 LuaJIT 中使用 FFI。
性能
其实标准 Lua 出于性能考虑,也内置了虚拟机 (Lua VM),所以 Lua 代码并不是直接被解释执行的,而是先由 Lua 编译器编译为字节码(Byte Code),然后再由 Lua 虚拟机执行。
而 LuaJIT 的运行时环境,除了一个汇编实现的 Lua 解释器外,还有一个可以直接生成机器代码的 JIT 编译器。
开始的时候,LuaJIT 和标准 Lua 一样,Lua 代码被编译为字节码,字节码被 LuaJIT 的解释器解释执行。
但不同的是,LuaJIT 的解释器会在执行字节码的同时,记录一些运行时的统计信息,当这些次数超过某个随机的阈值时,便认为对应的 Lua 函数入口或者对应的 Lua 循环足够热,这时便会触发 JIT 编译器开始工作。
编译的过程,是把 LuaJIT 字节码先转换成 LuaJIT 自己定义的中间码(IR),然后再生成针对目标体系结构的机器码。
所以,所谓 LuaJIT 的性能优化,本质上就是让尽可能多的 Lua 代码可以被 JIT 编译器生成机器码,而不是回退到 Lua 解释器的解释执行模式。
FFI
除了兼容 Lua 5.1 的语法并支持 JIT 外,LuaJIT 还紧密结合了 FFI(Foreign Function Interface),可以直接在 Lua 代码中调用外部的 C 函数和使用 C 的数据结构。
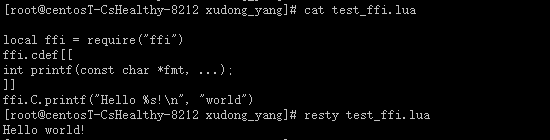
类似的,我们可以用 FFI 来调用 NGINX、OpenSSL 的 C 函数,来完成更多的功能。
实际上,FFI 方式比传统的 Lua/C API 方式的性能更优,这也是 lua-resty-core 项目(后面会介绍)存在的意义。
JIT 为什么不是全程编译?
既然编译过后效率更高,为什么不采用全程编译,而是只针对热代码编译?
时间
如果是少量运行,得不偿失
空间
编译后占用的内存会变大
JIT 编译优化需要运行的信息
并不是所有的编译执行都比解释执行效率高,给的运行时信息越多,效果越好