Redis 和 Memecache 的区别是什么?
1. Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。Memecache 支持简单的数据类型 String
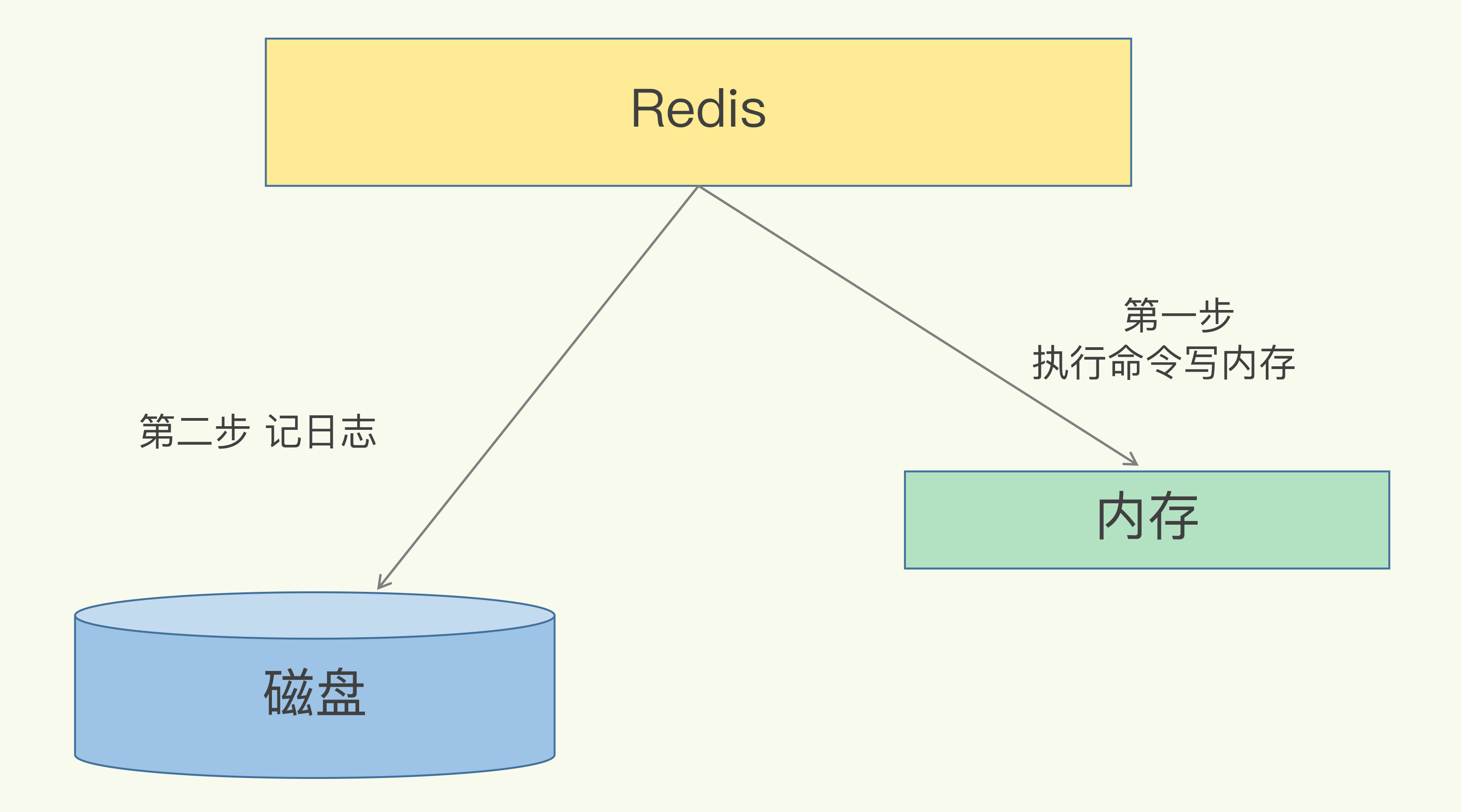
2. Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memecache 把数据全部存在内存之中
3. Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 Redis 目前是原生支持 cluster 模式的
4. Memcached 是多线程,非阻塞 IO 复用的网络模型;Redis 使用单线程的多路 IO 复用模型
Redis 常见数据结构以及使用场景分析?
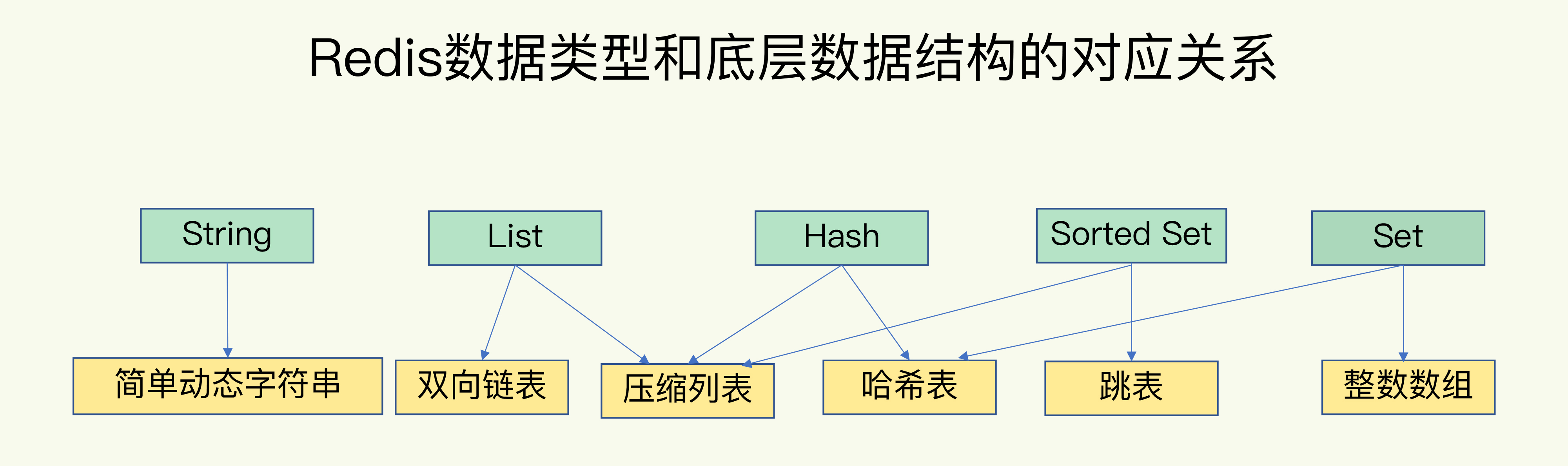
1. String 字符串
字符串类型是 Redis 最基础的数据结构,首先键都是字符串类型,而且其他几种数据结构都是在字符串类型基础上构建的。
常用在缓存、计数、共享 Session、限速等。
2. Hash 哈希
在 Redis 中,哈希类型是指键值本身又是一个键值对结构,形如 value={{field1,value1},...{fieldN,valueN}}。
哈希可以用来存放用户信息,比如实现购物车。
3. List 列表
列表(list)类型是用来存储多个有序的字符串。
可以做简单的消息队列的功能。另外,可以利用 lrange 命令,做基于 Redis 的分页功能,性能极佳,用户体验好。
4. Set 集合
集合(set)类型也是用来保存多个的字符串元素,但集合中不允许有重复元素,并且集合中的元素是无序的,不能通过索引下标获取元素。
利用 Set 的交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好等功能。
5. Sorted Set 有序集合
Sorted Set 多了一个权重参数 Score,集合中的元素能够按 Score 进行排列。
可以做排行榜应用,取 TOP N 操作
除此之外还有 3 个高级数据结构
1. Bitmaps bitmaps 应用于信息状态统计
2. HyperLogLog 应用于基数统计
3. GEO 应用于地理位置计算